KT(대표 김영섭)는 4일 글로벌 오픈 소스 커뮤니티 허깅페이스에 믿:음 2.0 모델 2종과 테크리포트를 공개했다. 기업과 개인, 공공 누구나 상업적으로 활용할 수 있는 MIT라이센스로 공개됐다.
▲범용 서비스에 적합한 '믿:음 2.0-베이스-11.5B' ▲온디바이스용 '믿:음 2.0-미니-2.3B' 2종이다.
소형 모델은 베이스 모델에서 증류한 지식을 학습한 것이다. 두 모델의 컨텍스트 창은 3만2000토큰이다.
KT는 테크리포트에서 "데이터의 양보다 질"을 강조하며, 고품질 한국어 데이터를 선별했다고 설명했다.
우선, 국내 교육용 도서와 문학 작품 등의 발간물, 법률 및 특허 문서, 각종 사전 등에서 확보한 데이터는 인문사회과학 분야에 편중되어 있다는 한계가 있었다고 지적했다. 따라서 도메인 불균형, 편향을 완화하기 위해 "사전학습 단계에서 고품질 합성 데이터를 전략적으로 통합했다"라고 설명했다.
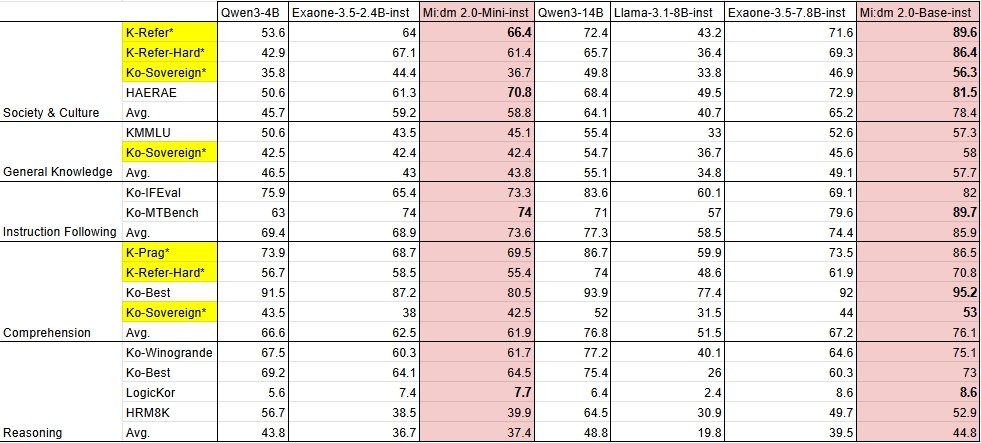
그 결과, 베이스 모델은 한국어 벤치마크에서 '큐원3-14B'와 '엑사원 3.5-7.8B'보다 높은 점수를 기록했다.
특히, KT는 한국 사회 및 문화적 맥락에 대한 추론 능력을 측정하기 위해 자체 벤치마크를 개발했다고 전했다.
베이스모델은 ▲한국어 참조(K-Referential) ▲고난이도 한국어 참조(K-Refer-Hard) ▲문화, 민속, 사회영역을 평가하는 코-소버린(Ko-Sovereign) ▲경어법, 중한 어휘, 고유어, 속담, 관용 표현 등에 대한 이해력을 테스트하는 한국어-실용어법(K-Pragmatics) 등에서 높은 점수를 기록했다.
이 중 코-소버린 벤치마크는 KT와 고려대학교가 공동 개발한 한국어 AI 역량 평가 지표다.
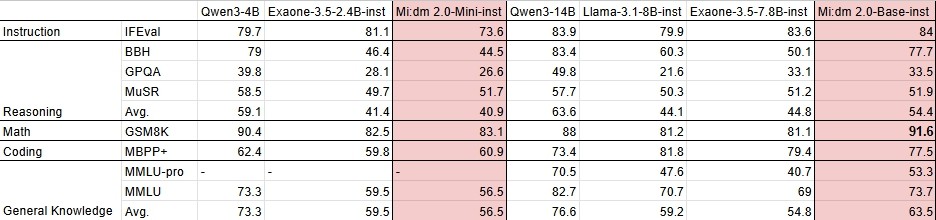
그러나 글로벌 기준인 영어 벤치 마크에서는 큐원3, 엑사원 3.5, 라마 3.1 등에 비해 전반적인 성능은 조금 못 미치는 것으로 나타났다.
단, 수학 능력을 평가하는 'GSMBK'에서는 베이스모델이 91.6점로 가장 높은 성적을 거뒀다.
한편, 전날 SK텔레콤이 '에이닷엑스 4.0' 2종을 공개한 것에 이어 국내 대기업이 연달아 모델을 오픈 소스로 공개하자, AI 서비스 기업들도 주목하고 있다.
여러 LLM을 적용해 무료 AI 서비스를 제공하는 뤼튼은 "국내외 다양한 LLM 개발 및 공개 동향을 항상 면밀히 살피고 있다"라며 "한국어에 특화된 다양한 국내 오픈 소스 모델들이 공개되는 것을 환영한다"라고 밝혔다.
다만, 실제 서비스에 적용하기 위해서는 "성능, 비용, 안정성 등 고려해야 할 요소가 많기 때문에 도입 여부를 결정하기에는 이른 단계"라고 전했다.
박수빈 기자 sbin08@aitimes.com
