오픈AI가 '챗GPT' 에 새로운 범용 인공지능(AI) 에이전트를 추가했다. 기존 GUI 에이전트인 '오퍼레이터(Operator)'에 심층 조사 기능인 '딥 리서치(Deep Research)'를 결합한 것을 특징으로 들었지만, 엑셀이나 파워포인트 자동 생성이 가능해진 점이 더 눈길을 끈다. 즉, 마이크로소프트(MS)와 구글이 점령한 기업 생산성 분야에 진입한 것이다.
오픈AI는 17일(현지시간) 사용자를 대신해 다양한 컴퓨터 작업을 수행할 수 있는 '챗GPT 에이전트'를 출시했다고 발표했다.
이날부터 챗GPT 프로와 플러스, 팀 등 유료 사용자를 대상으로 출시됐다. 도구를 활성화하려면 챗GPT 도구 드롭다운 메뉴에서 '에이전트 모드'를 선택하면 된다.
이는 오픈AI의 기존 에이전트 도구들의 여러 기능을 결합한 것으로, 사람 대신 웹사이트를 클릭하고 작동하는 오퍼레이터 기능과 방대한 웹사이트 정보를 종합해 심층적인 연구 보고서를 작성하는 딥 리서치 기능의 결합을 특징으로 들었다.
오픈AI는 "오퍼레이터로 시도한 많은 쿼리가 딥 리서치에 더 적합하다는 것을 확인했기 때문에 두 기능의 장점을 결합했다"라고 설명했다. 즉, 오퍼레이터는 심층 분석을 수행하거나 상세 보고서를 작성할 수 없었고, 딥 리서치는 웹사이트와 상호 작용해 결과를 구체화하거나 사용자 인증이 필요한 콘텐츠에 접근할 수 없었다는 것이다.
따라서 "챗GPT에 상호 보완적인 강점을 통합하고 추가 도구를 도입함으로써, 하나의 모델 내에서 완전히 새로운 기능을 구현할 수 있게 됐다"라고 설명했다.
이를 통해 앞으로 챗GPT는 웹사이트를 지능적으로 탐색하고, 결과를 필터링하고, 필요할 때 안전하게 로그인하도록 안내하고, 코드를 실행하고, 분석을 수행하고, 심지어 결과를 요약한 편집 가능한 슬라이드쇼와 스프레드시트까지 제공한다고 강조했다.
이처럼 기존의 오퍼레이터 기능을 더 강화한 것으로 볼 수 있다. 이제는 에이전트는 사용자를 대신해 호텔이나 식당을 예약하고 음식을 주문하는 것을 넘어, 딥 리서치를 통해 정교한 계획을 짜고 보고서까지 만들 수 있게 됐다는 것이 핵심이다.
따라서 "4인분 일본식 아침 메뉴를 준비해 줘"와 같은 명령에 레시피를 탐색하고 아침 준비 계획을 짠 뒤 이를 온라인으로 주문까지 해주는 일련의 행위가 가능해진다. 이전에는 오퍼레이터와 딥 리서치에서 일부 임무가 개별적으로만 처리할 수 있었다.
오픈AI는 별도로 강조하지 않았으나, 파워포인트와 엑셀 파일을 챗GPT가 스스로 만들 수 있다는 것이 가장 눈길을 끈다. 이는 앞서 디 인포메이션이 보도한 기업용 생산성 도구로의 진화를 말하는 것이기 때문이다.
현재 MS와 구글은 오피스나 워크플레이스 등 자사의 생산성 도구에 AI 기능을 탑재, 업무용 문서 생성에 활용하고 있다.
그러나 이제부터 챗GPT를 사용하면 이런 앱이 없이도 챗GPT가 관련 문서를 생성한다. 그것도 오픈AI가 보유한 가장 강력한 심층 분석 기능인 딥 러서치를 활용하는 것이다.
이는 챗GPT가 이제부터는 본격적인 생산성 도구로 진화했으며, MS와 구글에 도전장을 던졌다는 것을 의미한다.
또 새로운 에이전트는 챗GPT 커넥터에 접속해 사용자가 지메일이나 깃허브 같은 앱을 연결해 관련 정보를 찾을 수 있도록 지원한다. 이 또한 기업용 기능으로 볼 수 있다,
이처럼 이번 에이전트에는 최근 몇개월 동안 오픈AI가 기업용으로 개발했던 기능이 망라된 것으로 볼 수 있다.
다만, 오픈AI는 오퍼레이터, 딥리서치 출시 당시처럼 챗GPT 에이전트도 개선이 필요한 초기 단계라고 밝혔다. 케빈 와일 최고 제품책임자(CPO)는 “아직 완벽과는 거리가 멀다”라며 “6개월, 또는 1년 전 이런 일이 가능해졌으면, 우리는 정말 신났을 것”이라고 덧붙였다
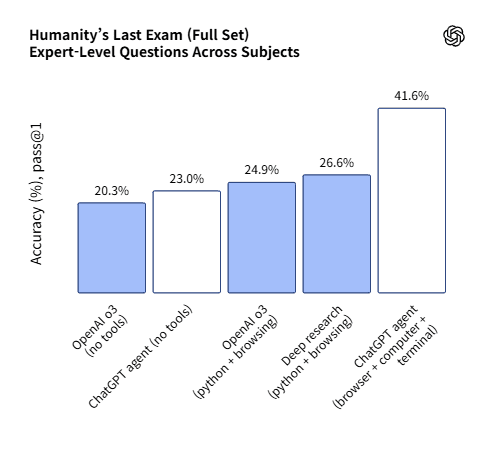
챗GPT 에이전트의 베이스 모델은 벤치마크에서 최첨단 성능을 선보였다.
가장 난이도가 높은 '인류의 마지막 시험(HLE)' 벤치마크에서 41.6%의 점수를 받았다고 밝혔다. 이는 'o3'나 'o4-미니'의 두배에 달한다.
수학 벤치마크인 '프론티어매스(FrontierMath)'에서는 코드 실행 터미널과 같은 도구를 사용할 때 27.4%의 점수를 기록했다. 이전 최고 점수는 o4-미니가 기록한 6.3%에 불과했다.
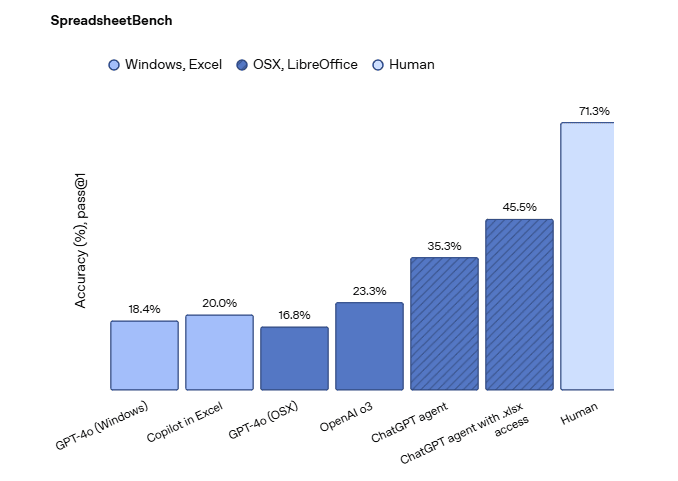
벤치마크에서도 가장 눈길을 끄는 것은 스프레드시트를 편집하는 능력 평가다. 챗GPT 에이전트는 '스프레드시트벤치(SpreadsheetBench)'에서 45.5%을 기록, MS의 '코파일럿(20.0%)'을 두배 이상 압도했다.
오픈AI는 챗GPT 에이전트를 개발할 때 안전성을 최우선으로 고려했다고 강조했다. 이 제품이 악의적인 행위자의 손에 들어가면 더욱 위험해질 수 있기 때문이다.
안전 보고서에서는 이 모델이 생화학 무기 분야에서 '고성능'으로 지정했다고 밝혔다. 이는 "기존 경로를 증폭시켜 심각한 피해를 줄 수 있는 능력을 가진 모델"이라는 뜻이다.
이에 따라 위험을 완화하기 위한 새로운 안전장치를 마련하기로 했다고 덧붙였다. 또 에이전트에 입력된 모든 프롬프트에 대해 분류기를 실행, 생물학과 관련이 있는지를 판별한다고 설명했다.
여기에 오용 방지를 위해 메모리 기능을 비활성화했다고 밝혔다. 이는 악의적인 사용자가 메모리 기능을 활용, 모델 탈옥을 유도하는 프롬프트 인젝션 공격이 가능하기 때문이라고 밝혔다. 하지만 앞으로 이 문제를 해결한 뒤 메모리를 추가할 가능성이 있다.
샘 알트먼 오픈AI CEO는 X(트위터)를 통해 "챗GPT 에이전트가 컴퓨터를 사용하여 복잡한 작업을 하는 것을 지켜보는 것은 정말로 '민첩성을 느끼는' 순간이었다. 컴퓨터가 생각하고, 계획하고, 실행하는 것을 보는 것은 뭔가 다른 차원이라는 것을 보여 준다"라고 말했다.
임대준 기자 ydj@aitimes.com
- 오픈AI, MS 앱 없어도 엑셀·파워포인트 만드는 '챗GPT' 기능 개발
- 오픈AI, 기업 맞춤형 모델 사업 본격화...B2B 대폭 강화
- [6월27일] 오픈AI, 생산성 앱 시장까지 점령할까...긴장하는 기업용 SW 업계
- 오픈AI, 문서 작업에 채팅 기능 추가 개발 중...MS 생산성 도구에 본격 도전
- 챗GPT 에이전트, '엑셀·PPT 사용'이 아니라 '직접 코드 생성'
- 오픈AI "챗GPT 에이전트 도입으로 역대 최강 보안 체계 구축"
- 챗GPT 에이전트, 캡차 인증 가볍게 통과...'나는 로봇이 아닙니다'
- 오픈AI, 연매출 16.7조 도달..'챗GPT' 주간사용자 7억 돌파
- MS, AI로 엑셀 작업 처리하는 ‘코파일럿’ 함수 시험 도입
- AI 인재 전쟁 속 ‘최강 수요 직종’은 여전히 MS 엑셀 전문가
- MS, 오픈AI 의존 벗어나 '코파일럿'에 앤트로픽 모델 도입
