
라쿠텐이 대규모 일본어 데이터셋으로 훈련한 대형언어모델(LLM)을 출시했다. 복잡한 일본어 문자를 처리하기 위해 토크나이저 어휘를 대폭 증가, 벤치마크에서 평균 68.74점을 기록했다는 설명이다. 이처럼 최근 일본어 모델의 성능이 빠르게 향상되고 있다.
기술 전문 매체 AIM은 최근 라쿠텐이 매개변수 70억개의 일본어 전문 LLM 제품군인 라쿠텐AI-7B를 오픈 소스로 출시했다고 보도했다.
이에 따르면 파운데이션 모델인 라쿠텐AI-7B는 방대한 영어와 일본어 텍스트 데이터를 학습했으며, 프랑스 미스트랄 AI의 오픈 소스 모델 가충치를 지속적으로 훈련해 개발됐다고 밝혔다.
일본어는 한자를 포함하고 있기 때문에, 영어나 다른 언어보다 스크립트 구조가 복잡하다. 이에 따라 텍스트를 모델에 맞게 조각화하는 토큰화 프로세스가 비효율적이고 추가 지원이 필요한 경우가 많아, 챗GPT와 같은 외산 모델이 좋은 성능을 발휘하기 어려웠다.
따라서 연구진은 토크나이저 어휘를 기존 3만2000개에서 4만8000개로 확장, 토큰당 문자 비율을 향상했다. 이를 통해 복잡한 일본 문자 처리 효율을 끌어올렸다고 설명했다.
더불어 엄격한 데이터 필터링 기술을 활용, 학습 데이터셋의 품질을 개선했다. 이를 통해 고품질의 1750억개 토큰으로 학습, 성능을 높였다고 소개했다.
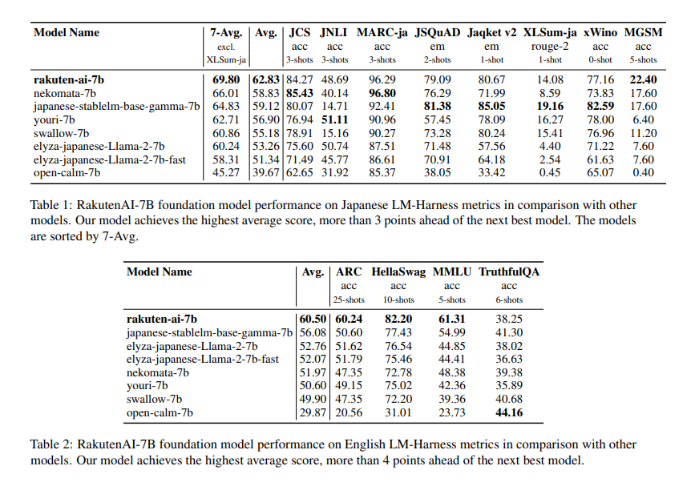
그 결과 이 모델은 일본어 모델 평가 벤치마크 하네스에서 평균 62.83을 기록, 일본어 오픈 소스 모델을 3점차 이상으로 앞지르며 1위를 차지했다. 또 강화학습을 적용한 '라쿠텐AI-7B-인스트럭트' 모델은 68.74점으로, 다른 모델(Youri-7B)보다 2점이 앞섰다.
팅 카이 라쿠텐 그룹 최고 데이터 책임자는 "이 모델을 통해 우리는 중요한 성능 이정표에 도달했으며, 우리가 배운 내용을 오픈 소스 커뮤니티와 공유하고 일본어 LLM 개발을 가속하게 돼 기쁘게 생각한다"라며 "우리는 최고의 도구를 활용해 기업의 문제를 해결하고 싶다"라고 말했다.
한편 일본에서는 라쿠텐 이외에도 NTT와 후지츠, NEC, 미츠이 등 대기업 중심으로 AI 분야의 빠른 진전을 이루고 있다.
NTT는 올봄에 일본어 능력에 초점을 맞춘 '츠즈미'라는 기업용 생성 AI 플랫폼을 출시할 예정이며, 후지츠는 도쿄공업대학, 이화학연구소(RIKEN), 도쿄기술연구소 등과 일본 슈퍼컴퓨터 ‘후가쿠(Fugaku)’를 활용한 300억 매개변수 오픈 소스 LLM을 개발 중이다.
NEC 역시 일본어 효율성에 중점을 둔 130억 매개변수의 일본어 LLM을 개발했다. 미츠이는 엔비디아와 협력, AI 모델을 통해 신약 개발을 지원하는 슈퍼컴퓨터 '도쿄-1'을 출시했다.
또 지난주에는 구글 트랜스포머 저자가 실럽한 사카나 AI가 모델 병합(Model Merge) 방식으로 성능을 향상한 일본어 모델 '에보LLM-JP' 등을 공개했다.
박찬 기자 cpark@aitimes.com
