
웨이모가 모회사 구글의 멀티모달대형언어모델(LMM)인 '제미나이'를 기반으로 자율주행 로보택시를 위한 새로운 훈련 모델을 개발하고 있다.
더 버지는 30일(현지시간) 웨이모가 자율주행을 위한 엔드 투 엔드 멀티모달 훈련 모델 ‘엠마(EMMA)’에 관한 연구 논문을 발표했다고 보도했다.
엠마는 센서 데이터를 처리해 자율주행 차량의 미래 궤적을 생성, 웨이모의 무인 차량이 이동 경로를 결정하고 장애물을 피하는 데 도움을 준다.
중요한 점은 자율주행 분야의 선두주자가 LMM을 실제 운영에 활용하는 첫번째 사례라는 것이다. 이는 현재 채팅봇, 이메일 정리, 이미지 생성과 같은 용도로 사용되던 LMM들이 완전히 새로운 환경인 도로에서 적용될 수 있다는 신호이기도 하다. 웨이모는 연구 논문에서 "LMM이 핵심 역할을 하는 자율 주행 시스템 개발"을 제안하고 있다.
이제까지 자율주행 시스템은 인지, 지도 작성, 예측, 계획 등 다양한 기능을 수행하기 위해 개별적인 특정 모듈을 개발해 왔다. 이런 접근 방식은 모듈 간 누적된 오류와 제한된 통신으로 인해 통합 및 확장에 문제가 있었다. 또 사전 정의된 구조로 인해 새로운 환경에 적응하는 데 어려움을 겪을 수 있다.
웨이모는 제미나이와 같은 LMM이 이런 문제를 해결할 방안을 제시한다고 주장했다.
그 이유는 두 가지다. 우선 LMM은 방대한 인터넷 데이터로 학습된 제너럴리스트(generalist)로, 일반적인 주행 기록에 포함되지 않은 풍부한 '세계 지식'을 제공한다.
또 LMM은 복잡한 작업을 논리적인 단계로 나누어 인간의 사고 과정을 모방하는 '생각의 사슬(CoT)'과 같은 기술로 우수한 추론 능력을 보여준다.
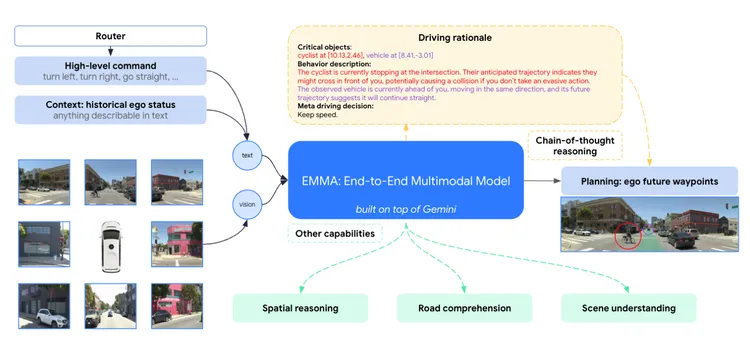
웨이모는 로보택시가 복잡한 환경을 안전하게 주행할 수 있도록 돕기 위해 엠마를 개발했다. 도로 위의 다양한 동물이나 공사 구간을 만나는 상황 등에서 이 모델이 자율주행 차량이 올바른 경로를 찾는 데 도움을 준 여러 사례를 확인했다고도 전했다. 경로 예측, 객체 감지, 도로 그래프 이해에서 뛰어난 성능을 발휘했다고 덧붙였다.
웨이모는 "이번 연구는 자율주행 작업을 확장할 수 있는 미래 연구의 유망한 방향을 제시한다"라고 말했다.
그러나 엠마에 한계도 있으며, 실제 적용 전에 추가 연구가 필요하다는 점을 인정했다. 예를 들어, 엠마는 계산 비용이 많이 드는 라이다나 레이더의 3D 센서 입력을 통합할 수 없고, 한번에 소량의 이미지 프레임만 처리할 수 있다는 것이다.
연구 논문에서 언급되지 않은 위험 요소도 존재한다. 제미나이 같은 모델은 환각을 일으키거나 시계 읽기나 물체 세기 같은 단순한 작업에 실패하기도 한다. 특히 자율주행 차량이 혼잡한 도로를 시속 60km로 달릴 때, 실수는 치명적이다.
이런 모델을 대규모로 배치하기 전에 더 많은 연구가 필요하며, 웨이모도 이 점을 분명히 하고 있다.
웨이모는 “이번 연구 결과가 문제를 완화하기 위한 추가 연구에 영감을 주고, 자율주행 모델 아키텍처의 최첨단 기술을 발전시키는 계기가 되길 바란다”라고 밝혔다.
박찬 기자 cpark@aitimes.com
