국내 최초의 전문 프롬프트 엔지니어가 최근 화제인 딥시크를 비롯, 국내외 대표적인 대형언어모델(LLM) 5종의 번역 능력을 비교 평가했다. 그 결과, 국내 스타트업 업스테이지의 ‘솔라’가 뛰어난 성능을 입증, 눈길을 모았다.
강수진 프롬프트 엔지니어는 2일 링크드인을 통해 국내외 대표 LLM 성능 평가 결과를 공개했다. 그는 업스테이지와는 관계가 없다.
지난 2023년 국내 최초의 프롬프트 엔지니어로 뤼튼테크놀로지스에 발탁, 화제를 모았던 인물이다. 현재는 더 프롬프트 컴퍼니의 대표로 활동하고 있다.
딥시크의 한국어 성능이 궁금했다는 것이 이번 실험을 진행한 계기라고 밝혔다. 이번 테스트에는 ▲딥시크챗을 비롯해 ▲GPT-4o ▲클로드 3.5 소네트 ▲제미나이 1.5 프로 ▲솔라-프로 등 5개 모델을 포함했다.
먼저 정성적인 부분의 측정을 위해 도널드 트럼프 미국 대통령의 취임사를 번역했다. 비교를 위해 인간이 직접 번역한 국내 매체의 번역문을 정답으로 참고했다.
그 결과 솔라 프로의 번역 결과가 인간 번역문과 가장 유사한 것으로 나타났다.
딥시크챗은 고유명사 정확도가 많이 떨어졌다. GPT-4o는 영문 표기를 그대로 유지했다. 제미나이 1.5 프로는 고유명사 및 핵심 문장 구조가 거의 일치하지만, 직역 문장이 많았다. 클로드 3.5 소네트는 한국어 표현이 가장 깔끔하고 유려하지만, 고유명사와 인명 표현에서 문제를 드러냈다.
문제점이 가장 적은 것은 솔라라고 평가했다. 원문을 그대로 옮기는 듯한 뉘앙스가 있지만, 인간 번역과 어순과 사용 단어가 가장 많이 일치했다는 분석이다.

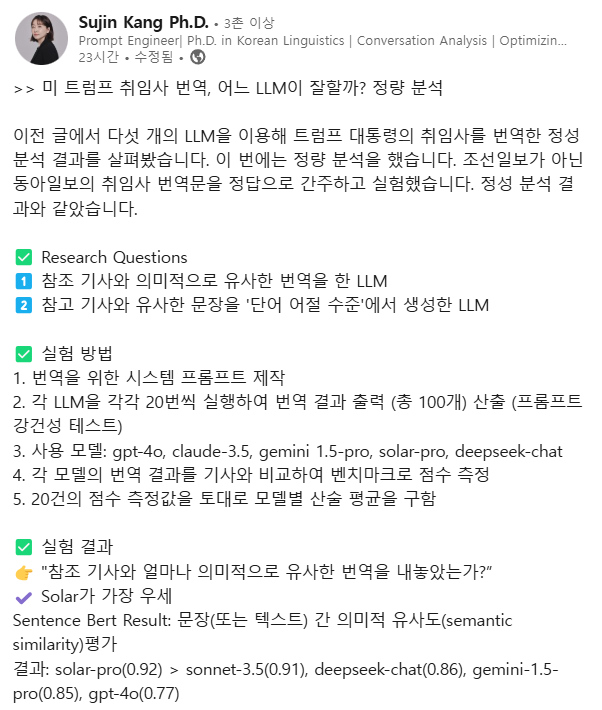
두번째로 진행한 정량 분석에서도 솔라-프로가 가장 좋은 성적을 거뒀다. 이번에는 다른 매체의 인간 번역문을 정답으로 설정했다.
이를 위해 ▲번역을 위한 시스템 프롬프트 제작 ▲LLM을 각각 20번씩 실행해 번역 결과를 총 100개 산출(프롬프트 강건성 테스트) ▲각 모델의 번역 결과를 기사 원문과 비교해 벤치마크로 점수 측정 ▲20건의 점수 측정값을 토대로 모델별 산술 평균 계산 등이 과정을 거쳤다.
정답과 의미상 유사 여부를 따지는 항목에서는 ▲솔라 프로 0.92 ▲소네트 3.5 0.91 ▲딥시크 챗 0.86 ▲제미나이 1.5 프로 0.85 ▲GPT-4o 0.77의 결과가 나왔다.
이어 단어-어절 수준으로 답을 세분화한 결과, 소네트 3.5가 가장 우세했다. 솔라-프로는 3위를 기록했다.
강수진 엔지니어는 “의미 유사도를 중요하게 생각한다면 솔라 프로를 추천하고, 어휘 및 구문 등 표현 유사도를 따진다면 소네트 3.5가 강점을 가진다"라고 정리했다.
한편, 업스테이지는 지난해 2월 한국어-영어 번역에 특화한 솔라 LLM의 API를 테스트 출시했다. “단순 문장 번역을 넘어 전후 문맥을 종합해 의미를 추론, 대화의 맥락과 흐름까지 파악하는 딥러닝 번역이 특징”이라고 설명했다.
관계자는 "솔라-프로 기반 번역 전문 서비스의 정식 출시는 아직 정해지지 않았다"라고 말했다.
장세민 기자 semim99@aitimes.com
