오픈AI가 5일(현지시간) 5년 만에 오픈 웨이트 모델을 공개했습니다. 매개변수 1200억개(120B)와 200억개(20B) 등 2종으로, 그리 적지 않은 크기에도 불구하고 온디바이스용으로 활용할 수 있을 만큼 효율을 높였다는 것이 눈길을 모았습니다.
역시 가장 관심을 끄는 것은 성능입니다. 샘 알트먼 오픈AI CEO는 "오픈 모델 중 최강 성능"을 목표로 했다고 밝혔고, 오픈AI도 자체 벤치마크를 통해 그렇다고 강조했습니다.
오픈AI에 따르면, 새로운 오픈 모델은 현재 보유한 최고 성능 'o3'에는 못 미치지만, 그다음으로 꼽히는 'o4-미니'와 비슷하며 'o3-미니'에는 앞서는 것으로 나타났습니다.
특히, 이 모델을 내놓게 된 동기가 '딥시크'와 같은 중국 오픈 소스였기 때문에, 수학이나 코딩에서 이들보다 뛰어나다는 점을 암시했습니다.
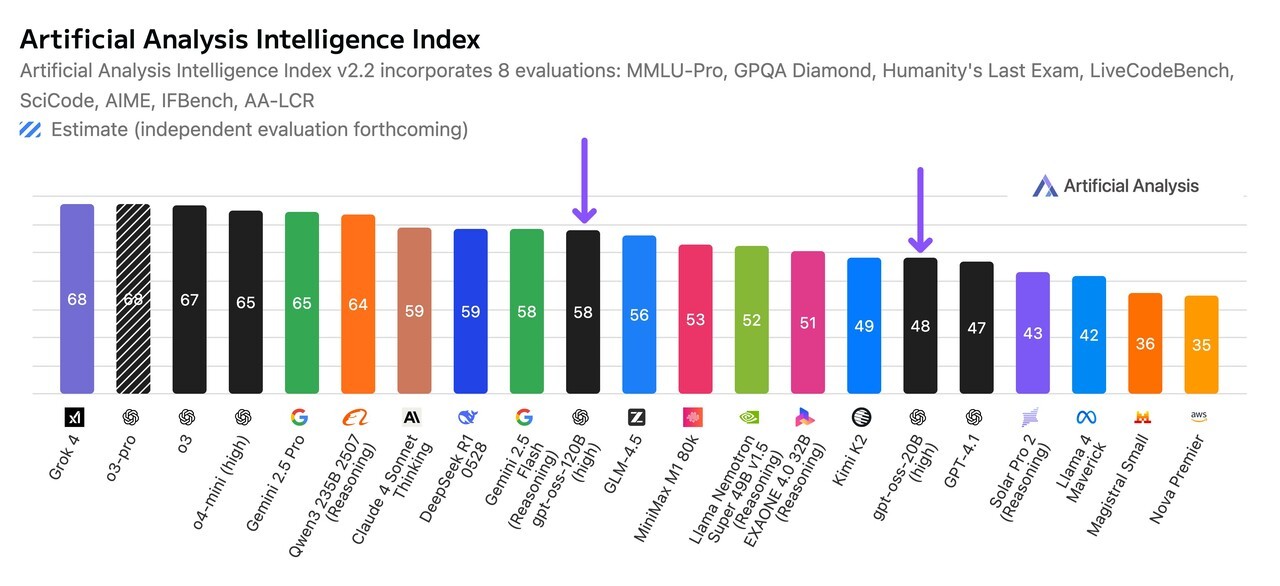
그러나, 중요한 것은 외부 평가입니다. 출시 다음날인 6일에는 유명 벤치마크 전문 아티피셜 애널리시스(Artificial Analysis)가 분석을 내놓았습니다.
이 회사는 최근 주요 AI 개발사의 기술 보고서에도 자주 등장하는 곳입니다. 국내에서는 지난달 LG AI연구원과 업스테이지가 '엑사원 4.0'과 '솔라 프로 2'의 성능을 보여주기 위해 인용한 바 있습니다,
결론부터 말하자면, 종합적인 성능에서 오픈AI의 모델들은 '딥시크-R1'이나 '큐원 3'를 잡는 데 실패했습니다. 아티피셜 애널리시스 종합 순위에서 120B 모델은 10위(평균 58점), 20B 모델은 16위(48점)를 차지했습니다. 반면, '큐원 3 235B'는 6위(64점), 딥시크-R1은 8위(59점)입니다.
더 눈길을 끈 것은 LG AI연구원의 '엑사원 4 32B'가 14위(51점)로, 사이즈가 비슷한 오픈AI의 소형 모델을 앞섰다는 점입니다.
이런 결과가 나온 것은 오픈AI의 모델이 수학과 코딩 능력에 집중됐기 때문입니다. 하지만, 이번 점수 측정은 'MMLU-프로'나 'GPQA 다이아몬드', '인류의 마지막 시험(HLE)' 등 지식 분야가 포함됐습니다.
오픈AI 모델은 수학과 코딩에서는 경쟁력을 갖춘 것으로 나타났습니다. 120B 모델은 'AIME 2025'에서는 6위, '라이브코드벤치'에서는 10위에 올랐습니다.
하지만, 모델의 지식을 테스트하는 분야에서는 모두 10위 밖으로 밀려났습니다. 즉, 이 모델은 수학과 코딩에는 강하지만, 글쓰기나 창의적 사용에는 첨단 모델에 못 미친다는 결론입니다.
이런 분위기는 벌써 커뮤니티에서도 등장하고 있습니다. AI 인플루언서 리산 알 가이브는 X(트위터)를 통해 "솔직히 벤치마크 외에는 뭐가 좋은지 모르겠다"라며 "그냥 수학 모델일 뿐인가"라고 지적했습니다.
또 일반적인 글쓰기 결과에 수학 공식을 삽입하는 코믹한 현상이 등장했습니다. 사우어스라는 사용자는 시 중간에 적분 공식을 집어넣은 스크린샷을 공유했습니다.

이런 이유에 대해, 저작권 문제를 피하기 위해 합성 데이터를 주로 사용했기 때문이라는 분석도 나왔습니다.
물론, 외부 벤치마크는 아직 아티피셜 애널리시스 한곳만 등장했고, 사용자 반응도 초기의 극단적인 사례에 불과합니다. 좀 더 지켜볼 필요가 있습니다.
또 5년 만에 처음으로 내놓은 오픈 모델이라, 수년 간 커뮤니티의 지원으로 성장한 다른 모델과 비교하는 것 자체가 무리일지 모릅니다. 즉, 오픈AI 모델도 업데이트를 거듭하면 다른 곳을 능가할 가능성은 충분합니다.
이처럼 거의 처음으로 오픈 모델을 내놓았다는 자체가 가장 중요하다는 의견이 많습니다. 또 온디바이스 AI 지원과 빠른 응답 시간, 기존 모델 10분의 1 수준인 저렴한 API 가격 등으로 누구나 쉽게 사용할 수 있도록 한 것은 생태계에 큰 도움이 된다는 것입니다.
유명 평론가인 이선 몰릭 펜실베이니아대학교 와튼 경영대학원 교수나 미국의 오픈 소스 프로젝트를 이끄는 구글 출신 네이선 램버트, 클렘 들랑그 허깅페이스 CEO 등은 오픈AI의 시도 자체를 칭찬하며, 앞으로 더 지켜볼 필요가 있다고 밝혔습니다.
이어 6일 주요 뉴스입니다.

■ 구글, 월드모델 '지니 3' 출시..."AGI 향한 일보 진전"
구글이 물리적 일관성과 장기 기억까지 갖춘 월드 모델 최신 버전을 공개했습니다. 이 두가지 요소는 AI가 현실 세계를 이해하고 반영하는 '물리 AI'의 핵심 요소이기도 합니다. 이를 통해 게임 제작을 넘어, 에이전트나 로봇으로 적용이 확대할 수 있다고 합니다.
■ 앤트로픽, GPT-5 대응 '클로드 오퍼스 4.1' 출시..."코딩 성능 향상"
앤트로픽이 기습적으로 클로드 오퍼스 최신 버전을 내놓았습니다. 이는 GPT-5의 코딩 성능이 기존 오퍼스 4.0보다 뛰어나다는 사실을 덮기 위한 것으로 보입니다. 무슨 수를 써서라도 코딩 1등만큼은 놓치지 않겠다는 것입니다.
■ 프렌들리AI, '사용자가 평가하는' 모델 비교 플랫폼 'WBA' 오픈
2년 전부터 미국에서 인기를 끈 인간 선호도 벤치마크 LMSYS와 흡사한 국내 버전이 등장했습니다. 프렌들리AI에서도 'WBA'라는 사이트 를 론칭했는데, 앞으로 어떤 결과가 나올지 주목됩니다.
AI타임스 news@aitimes.com
