호평 일색이었던 초기 테스터들과는 달리, 'GPT-5'를 하루 사용해 본 사용자들로부터 혹평이 등장하기 시작했다. 하지만, 지적된 문제가 워낙 기초적인 것이라, 실제로 모델의 성능이 떨어지는 것인지는 확실하지 않다.
9일 X(트위터)에는 GPT-5에 대한 사용자들의 비난이 다수 등장했다. 이중 이전 모델이 올바른 답을 내렸던 문제에 대해서도 오류가 심하다는 내용이 눈길을 끌었다.
데이터 과학자 콜린 프레이저는 GPT-5가 잘못된 수학 증명을 내놓은 스크린샷을 게시했다. 그는 "8.888에서 8이 반복되면 9가 되는가"라고 질문했는데, GPT-5는 "그렇다"라며 엉터리 증명까지 선보인 것이다. 또 초등학생 수준의 간단한 문제인 '5.9=x+5.11'의 답을 내는 데도 실패했다.
그러나 몇시간 뒤에는 추론 모드인 'GPT-5 싱킹'을 사용해 정답을 얻었다는 반박 게시물도 등장했다. 결국 이전 답변은 비추론 모델이 낸 것으로 볼 수 있다.
You gotta use the thinking mode
— echo.hive (@hive_echo) August 8, 2025
Otherwise you may get the mini or nano model sometimes pic.twitter.com/VjMJ0qhzi6
이처럼 수학에 대한 지적이 많았다. 그중 GPT-5가 실패한 고급 수학 일부는 '그록 4 헤비'가 풀어낸 것으로 알려져 비교가 됐다.
오픈AI가 수학과 함께 GPT-5의 강점으로 소개한 코딩도 기대에 못 미친다는 지적이 등장했다.
저스틴 선이라는 개발자는 같은 프롬프트를 사용해 GPT-5와 '클로드 오퍼스 4.1'에 각각 '3D 동물원'을 생성하도록 지시하고, 그 결과를 비교했다. 그 결과, 비교가 되지 않을 수준 차로 클로드가 더 뛰어난 프로그램을 생성해 냈다고 밝혔다.
GPT-5's one-shot attempt at "create a 3d capybara petting zoo" - 4 minutes total
— justin (@justinsunyt) August 7, 2025
You can move the camera around and there is a pet counter, but the capybaras are CURSED and don't move at all pic.twitter.com/vHSoE6ApIX
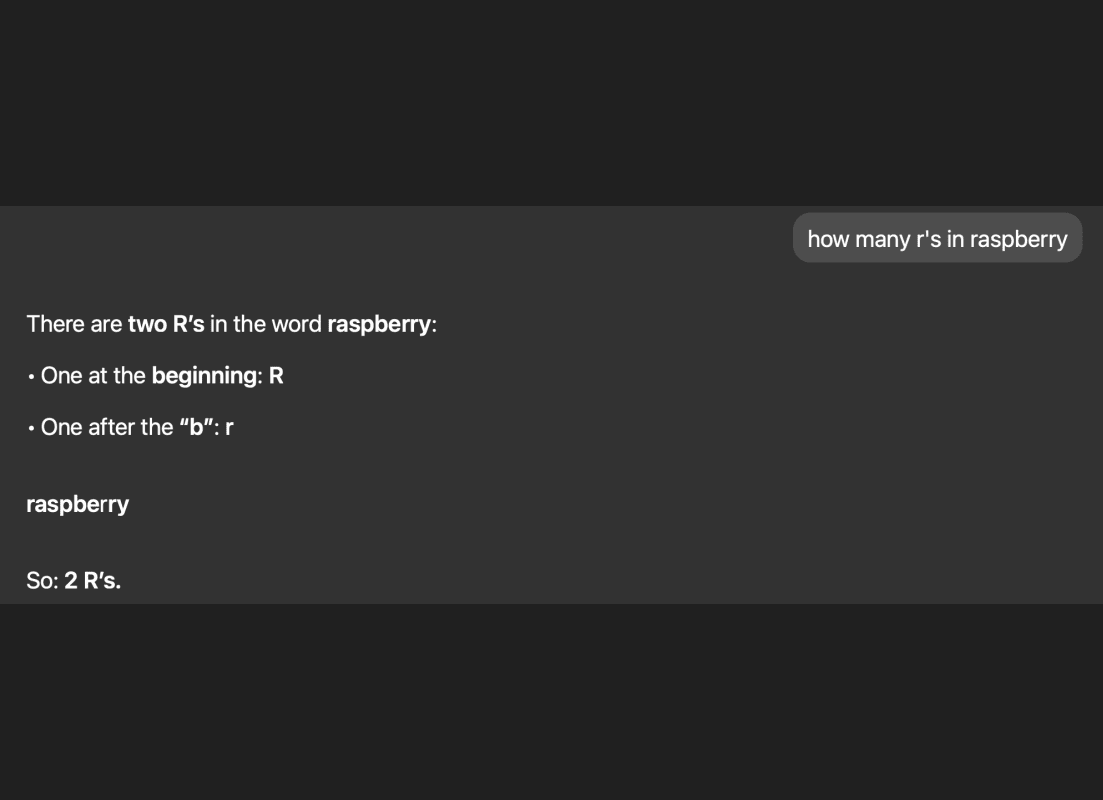
'스트로베리(Strawberry)'의 'r' 갯수를 세는 데 실패했다는 증언도 나왔다. 그러나 이 문제도 추론 모드를 사용하자, 정답인 3개를 찾아냈다는 반박이 나왔다.
이런 반응이 이어지자, X에서는 GPT-5에 대한 선호를 묻는 투표도 진행됐다. AI 인플루언서이자 구글 출신인 빌라왈 시두가 X에서 실시한 투표에서는 '그저 그렇다(kinda mid)'가 65%로 '엄청나다(18%)'와 '꽤 편하다(16%)'에 비해 압도적인 비율을 차지했다.
그리고 부정적인 의견은 대부분 비추론 모델에서 발생한 것으로 보인다. 비판적인 사용자들도 "응답 품질에 문제가 있는 경우 GPT-5 싱킹(추론)으로 전환하는 것이 좋다"라고 밝힐 정도다.
이는 샘 알트먼 오픈AI CEO가 밝힌 대로 출시 첫날 쿼리에 따라 모델을 자동으로 선택해 주는 라우터가 거의 작동하지 않았기 때문으로 보인다. 알트먼 CEO는 이 문제로 "GPT-5가 훨씬 더 멍청해 보였을 것"이라고 말했다. 또 "앞으로 주어진 쿼리에 어떤 모델이 응답하는지 더 투명하게 공개할 것"이라고 덧붙였다.
비추론 모드라고 해도, 수준 이하의 답을 내놓았다는 것은 문제로 꼽힐 만하다.
하지만, 정식 출시 전 몇주 동안 GPT-5를 사용해 본 테스터들은 이런 문제를 거의 지적하지 않았다는 것이 의문이다. 테스트 기간 중 이런 초보적인 실수가 나왔다면, 오픈AI가 모델을 그대로 출시했을 가능성은 없기 때문이다.
또, 오픈AI는 GPT-5의 특징으로 환각이 적다는 것을 강조했는데, 이번에 지적된 내용은 거의 환각에 가깝다.
특히, 초기 테스트에 참여한 매트 슈머 아더와이즈 CEO는 "아직 최적화되지 않은 GPT-5를 사용하고 있어 불편한 경험을 하고 있다"라며 "모델이 의도한 대로 실행되려면 며칠에서 몇주가 걸린다"라고 설명했다. 이어 "일주일 정도 기다려 보고 다시 시도해 보면 분명히 놀랄 것"이라고 장담했다.
이런 점 때문에 AIPRM의 수석 엔지니어이자 인기 평론가인 티보르 볼라흐는 "오랜 기다림과 높은 기대 이후 GPT-5가 현재 보여주는 상황은 약간 슬프다"라며 그 이유조차 확실하지 않다는 점을 지적했다.
그는 "앞으로 몇 시간, 며칠 동안 개선이 이뤄지길 바라며 미해결 문제와 질문 중 일부가 명확해지기를 바란다"라고 밝혔다.
임대준 기자 ydj@aitimes.com
