
스스로 코딩을 학습해서 프로그래밍을 하고, 시(詩)를 번역해내는 자연어처리(NLP) 인공지능 모델 GPT3(Generative Pre-Training 3) '충격파'가 업계를 뒤흔들고 있다. 검색량이 급증하며 경탄하는 반응부터, 과장왜곡을 경계해야 한다는 지적도 잇따른다.
27일 구글애널리스틱(GA) 분석 결과, GPT3 논문이 공개된 지난 달 대비 'gpt3ㆍ오픈ai' 검색지수가 1000% 가량 폭증했다. 전월 대비 네이버 검색지수도 최고치를 찍었다. 이번 달 오픈AI가 개발자들에게 API를 제공, 전세계에서 활용 사례들이 쏟아지고 있기 때문으로 보인다.
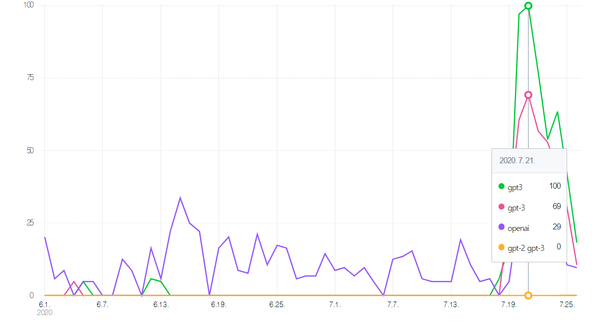
반면, GPT-3의 한계를 왜곡하거나 과장해서는 안된다는 주장도 쏟아지고 있다.
벤처캐피탈리스트로 포브스지 AI컬럼니스트로 활동 중인 롭 토우(Rob Toews)는 기고를 통해 "Gpt-3에 대한 광범위한 오해와 과장이 있다"면서 "추론(Reasoning) 능력이 떨어지는 GPT-3가 할 수 있는 것과 할 수 없는 것을 분명한 시각으로 구분해야 한다"고 지적했다.
오픈AI CEO 샘 알트만(Sam Altman)도 트위터를 통해 "AI는 세상을 바꿀 것"이라면서 "GPT3는 이제 그 시작일 뿐이며 현재 과도하게 포장되어 있는 것 같다"고 지적했다. 즉, GPT-3가 길이가 긴 구절이나 문맥에서 일관성을 잃거나 모순될 수 있다는 한계를 인정한 것이다.
경희대 이경전 교수는 "GPT-3는 인류의 대단한 성취이긴 하다"면서도 "국내든 국외든 GPT-3를 찬양만 하는 전문가가 있다면 그는 전문가가 아닐 것"이라고 꼬집었다.
미디어고토사의 이성규 대표도 "한국의 현실을 돌아봐야 한다. 막상 한국어를 대상으로 GPT3같은 언어 모델을 만든다고 가정해보면 1차 사전 학습 위한 대규모 데이터는 어디서 구할 수 있을까"라는 질문을 던졌다. 그는 "일부 대형 IT기업이 아니라면 한국어 빅데이터는 찾기 어렵다. 개인은 시도조차 하지 못할 것"이라고 지적했다.
전 교육과학기술부 김창경 차관은 "GPT3는 유료로 제공된다. 오픈AI는 인공지능이 인류를 상대로 주도권을 잡지 않게 하기 위해서 만든 비영리 단체인 것으로 알고 있었는데 무척 당혹스럽다"고 지적했다.
김 전차관은 "학생들이 GPT3를 제대로 사용하기 시작한다면 그들은 더 이상 가르칠게 없을 것"이라며 "GPT3는 대학 와해의 전주곡"'이라고 기대와 우려 간 균형 감각을 강조했다.
GPT3(Generative Pre-Training 3): 오픈AI(OpenAI)가 개발한 초대형 인공지능형 자연어 생성 모델. 지난 6월1일 아카이브(arXiv)를 통해 연구 논문(Language Models are Few-Shot Learners)을 공개했다. 무려 31명의 공동 저자가 발표한 74쪽 분량.
오픈AI는 전기차 테슬라와 항공우주 스페이스X 등으로 유명한 일론 머스크(Elon Reeve Musk)가 창립한 비영리 인공지능 연구단체.
논문에 따르면, GPT3는 약 4990억개 데이터셋 중 가중치 샘플링을 한 3000억여개의 데이터 셋으로 자체 감독학습(self-supervised learning)을 통한 사전 학습을 거쳤다. 1750억개의 매개변수를 적용.
자연어 기계 번역을 위해 도입된 어텐션 메커니즘(Attention Mechanism)과 RNN, LSTM 없이 타임드 시퀀스(Timed Sequence) 역할을 하는 트랜스포머(Transformer) 등 표준 개념과 커먼 크롤(Common Crawl) 등 데이타를 사용했다.
상식선에서 이해를 돕기 위해 쉽게 말하자면, 이세돌 기사를 바둑에서 이긴 알파고가 수많은 기보를 스스로 학습했듯이, GPT-3는 수년간 인터넷에 올라온 모든 문서를 끌어와 5조 단위의 데이터 세트를 기계학습(Machine Learning)으로 분석해낸 셈이다. 키워드를 제시하면, 알고리즘 및 사전학습 된 상식추론 등을 통해 대응한다.
인공지능(AI) 자연어 처리(NLP)분야에서는 지금까지 구글의 언어모델 버트(Bert)가 양방향 형으로, OpenAI의 GPT-2가 단방향으로, 각각 주목받았으며, 이외 기계신경망 번역(Transformer) 모델 등이 있다.
