실제 세계에서 작동할 수 있는 인공지능(AI)을 만드는 건 AI 연구자들의 오랜 목표였다. AI 로봇이 실제 사물에 동작하도록 훈련시키는 연구가 최근 공개됐다. 서랍장을 여닫는 등 실제 물체를 사용하는 AI로봇이 개발될 것이라는 기대가 실리는 지점이다.
지난 7일 스탠포드대와 페이스북 AI연구소가 공동 발표한 논문 ‘행동지점: 관절형 3D 물체를 픽셀로 인식해 동작하게 하는 방법(Where2Act: From Pixels to Actions for Articulated 3D Objects)’에 따르면 연구진은 움직이는 부품(movable part)을 지닌 물체를 밀거나 당기는 등 동작 관련 정보를 추출해, AI모델에게 훈련시키는 방법을 제안했다.
AI가 서랍장의 손잡이에 당기는 힘을 가하면, 그 서랍장이 열릴 것이란 사실을 예측하는 훈련이다.
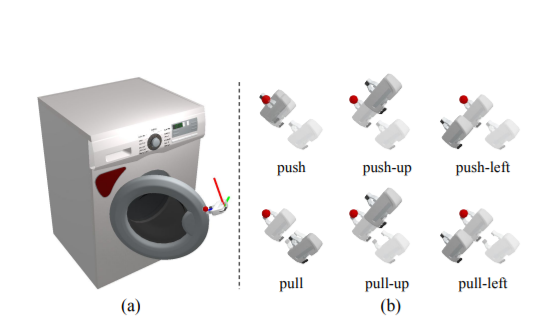
연구진은 사물을 움직이는 일련의 과정을 '단기' 작용의 연속으로 봤다. 이에 로봇은 물체의 상태를 보고 수행할 수 있는 작업을 판단해 밀고 당기기 등 부분 동작으로 구분한다. 부분 동작은 다시, '어디서'와 '어떻게'로 세분화된다. 예를 들어, 로봇이 서랍장의 어느 손잡이를 잡아당겨야 하는지 혹은 평행 또는 수직으로 당겨야 하는지 여부 등이다.
연구진은 이러한 과정을 조밀한 픽셀 단위의 시각적 예측을 통해 공식화했다. 모델에게 물체의 시각적 깊이, 색상 이미지를 분석해 특정 동작의 실행 여부를 추론하게 한 것. 모델은 각 픽셀 범위에 ▲동작 실행 가능성(actionability) ▲동작 제안(action proposals) ▲성공 가능성(success likelihoods) 점수를 부여해, 물체를 움직일 수 있는지 스스로 판단한다.

연구진은 “AI모델이 물체의 기하학적 특징을 추출해, 특정 동작과 손잡이를 인식하는 방법을 배운다”고 설명했다. 서랍장을 당겨야 할 땐, 부품 경계와 손잡이처럼 곡률이 높은 영역에 주목하는 식이다. 반면 밀기의 경우, 밀 수 있는 평평한 표면을 가진 픽셀에 주목한다. 이때 손잡이는 앞선 분석에 따라 밀 수 없는 것으로 예측한다.
연구진은 효율적인 상호작용 실험을 위해 시뮬레이션 환경을 이용했다. 한편 연구진은 이런 학습 시스템을 이용하면, 모델이 실제 세계를 스캔과 이미지화를 통해 일반화한다는 사실도 발견했다.
연구진은 실내에서 흔히 볼 수 있는 972개 모양의 물체를 15개의 카테고리로 분류해, 물체에 상호작용하는 6가지 유형을 학습하고 실험했다. 이때 부품 감지와 동작 속성을 인식하는 상호작용 시뮬레이션 프로그램 '사피엔(Sapien)'을 이용했다. 실험에서 연구진은 오픈 소스 데이터 세트에서 얻은 실제 세계의 3D 스캔에 이 AI모델이 동작 예측 점수를 부여하는 것을 시각화했다.
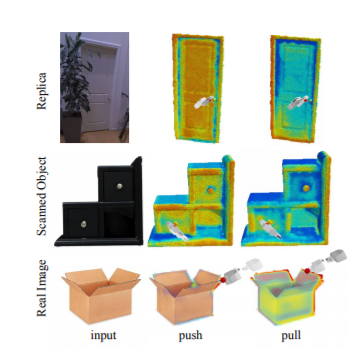
연구진은 “관절 구조로 연결된 바깥의 부분은 경우 동작 예측을 보장할 수 없다”라며 “하지만 전체적인 구조에 동작을 적용한다면 결과는 합리적이었다”라고 설명했다.
이어 연구진은 연구에 한계가 있단 사실도 인정했다. “학습 모델에 단일 구조만 입력할 수 있다. 관절형 부품이 움직이는 경우 그 결과가 모호하고 하드 코딩(hard-code·데이터를 프로그램 소스 코드에 직접 포함하는 소프트웨어 개발 방식)된 움직임의 궤적을 좆는 것도 제한적이다”라며 “하지만 향후 연구에서 상호작용을 자유롭게 하기 위해 모델을 일반화할 계획이다”라고 말했다.
AI타임스 장희수 기자 heehee2157@aitimes.com
