
인공지능(AI) 전문 크라우드웍스(대표 김우승)는 기업 비즈니스 특화 소형언어모델(sLM) '웍스원(WorksOne)'을 개발했다고 25일 밝혔다.
웍스원은 알리바바의 '큐원(Qwen)' 모델을 베이스로 사용했다. "국내 비즈니스 용어를 가장 잘 이해할 수 있는 언어모델"이라는 설명이다.
지난해 9월부터 8개월 간의 프로젝트를 진행한 결과, 창립 7주년을 맞이하는 날에 공개하게 됐다.
크라우드웍스는 그동안 영어 중심 대형언어모델(LLM)의 취약점을 발견해 왔다. 한국어는 물론 국내 비즈니스 용어를 제대로 이해하지 못해 기업의 수요를 충족하기가 어려웠다고 전했다.
문제 해결을 위해 가장 공을 들인 부분은 데이터다. 1만개에 달하는 고품질 데이터셋으로 학습, 기업이 선호하는 비즈니스 친화적인 답변을 제공한다고 강조했다.
특히 단순 번역형 데이터의 한계를 벗어나기 위해 직접 데이터 구축에 나섰다는 설명이다.
데이터셋은 금융, 유통, 공공기관 등 기업별 데이터 특징을 분석하는 것부터 시작했다.
비즈니스 특화 용어, 문체, 보고 유형 등을 분석했다고 전했다. 시중에서 흔히 접할 수 있는 번역 데이터에는 오류가 다수 포함될 수 있어, 모델이 문맥을 잘못 이해하거나 부정확한 판단을 내릴 수 있기 때문이다.
고급 데이터 작업자를 선발, 비즈니스 언어 활용과 표현력, 문서 구조화 능력 등 자체 검증을 실시했다.
기업 내부 시스템과 연동이 원활한 것도 강점으로 꼽았다. 웍스원은 지정한 키(Key) 값과 구조를 갖춘 제이슨(JSON) 형식의 답변을 안정적으로 출력할 수 있다.
사내 레거시 시스템과의 통합 및 확장이 용이해 데이터 교환이나 상호 운용성을 향상할 수도 있다.
자체 테스트 결과 한국어 환경에서 챗GPT나 다른 모델보다 뛰어난 성능을 보였다고 밝혔다. 노이즈나 항목 누락 없이 안정적으로 답변을 생성했다고 전했다.
"한 답변에 띄어쓰기 혹은 오타 하나만 발생해도 사용자가 전후처리에 상당한 리소스를 소모하는 것이 현실"이라며 "이 때문에 정확한 답변을 안정적으로 출력할 수 있는 것은 매우 중요하다"라고 강조했다.
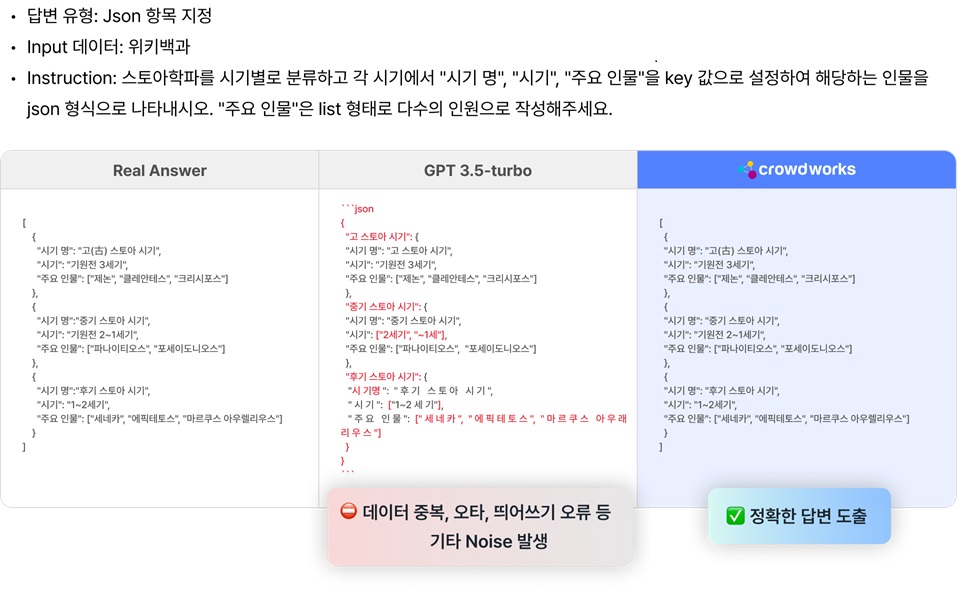
모델 성능 평가를 위한 샘플 테스트를 진행했다. 사용자가 지시한 키 값을 설정해 답변을 JSON 형식으로 나타내는 동시에, 스토어 학파의 주요 인물을 리스트 형태로 작성하라는 지시를 내렸다.
그 결과 'GPT-3.5 터보'는 데이터 중복, 오타, 띄어쓰기 오류 등의 노이즈가 발생, JSON 형식의 답변을 안정적으로 출력하지 못했다.
한국어 환경에서는 웍스원이 매개변수가 훨씬 큰 모델보다 월등한 결과를 나타냈다고 밝혔다.
한편 크라우드웍스는 앞으로도 LLM 사업에 집중하겠다고 전했다.
관계자는 "아직 초기 시장이기 때문에 예상 매출을 언급하기엔 조심스럽지만, 기업들이 비용이나 보안 상 이유로 파운데이션 모델을 그대로 사용하기 어려워하는 것은 사실"이라며 "sLM을 선호하는 만큼, 앞으로 수요는 계속 늘어날 것"이라고 말했다.
또 차별화된 데이터를 중심으로 한 문제 정의, 데이터 구축 및 자산화를 시작으로 모델 구축, 애플리케이션 개발, 데이터 및 모델 평가까지 풀스택 서비스를 제공해 AI 시장 경쟁력을 확보하겠다는 의도다.
이미 여러 산업군에 LLM 구축 사례를 레퍼런스로 쌓은 만큼, 이를 기반으로 영업도 확대할 계획이다.
이형주 크라우드웍스 CTO는 “비즈니스 용어 및 문서 환경에 대한 이해도가 높은 전문가가 직접 만든 한국어 데이터로 학습시킨 결과"라며 "비즈니스 특화 모델로서 이러한 고품질 데이터로 학습한 모델은 업계에서 유일하다”라고 말했다.
또 “앞으로도 AI 데이터부터 LLM까지 기업 혁신에 필요한 모든 것을 제공하겠다”라고 말했다.
장세민 기자 semim99@aitimes.com
