
중국이 오픈 AI(OpenAI)의 'GPT-3'나 구글(Google)의 'PaLM'에 대적할 대규모 언어 모델을 공개했다.
중국 칭화대학(Tsinghua University) 연구진이 중국어와 영어로 구성된 4000억개 이상의 텍스트 토큰으로 훈련한 1300억개의 매개변수를 가진 개방형 이중 언어 모델 'GLM-130B'를 공개했다고 믹스드(Mixed)가 27일(현지시간) 보도했다.
언어와 이미지 모델 또는 코드 모델을 위한 대규모 AI 모델은 인공지능(AI) 보급의 첨병 역할을 해왔다. 미국 오픈AI가 최초의 대규모 언어모델인 GPT-3를 출시한 것을 시작으로 구글의 PaLM, 메타의 OPT 모델, 빅사이언스(BigScience)의 BLOOM, AI21 Labs의 Jurassic-1, 알레프 알파(Aleph Alpha)의 Luminous 등이 속속 등장했다.
오픈AI는 마이크로소프트(MS)와 협력해 깃허브(Github) 데이터를 사용한 대규모 코드 모델 코덱스(Codex)도 내놓았다. 코드 모델은 구글, 아마존(Amazon), 딥마인드(Deepmind), 및 세일즈포스(Salesforce)에서도 사용할 수 있다.
이들 모델은 대부분 서양 데이터로 훈련, 중국에서는 액세스가 불가능하거나 가능하더라도 사용하기에 적합하지 않은 상태였다.
이에 중국에서는 화웨이(Huawei)가 지난해 11테라바이트 용량의 중국어 데이터를 가지고 훈련한 2000억 매개변수 언어모델인 'PanGu-Alpha'를 선보인 바 있다. 베이징 AI 아카데미(BAAI)도 1조 7500억개의 매개변수 다중 모드 모델인 'Wu Dao 2.0'을 내놓았다.
이번에 이중 언어모델 'GLM-130B'를 공개한 칭화대학은 벤치마크에서 메타의 OPT, BLOOM, 오픈AI의 GPT-3의 성능을 능가하는것으로 나타났다고 소개했다. 특히 소량의 데이터로 새로운 작업을 학습할 수 있는 중국어 및 영어 모델의 퓨샷 러닝(Few-Shot learning) 성능은 MMLU(대규모 다중 작업 언어 이해) 벤치마크에서 이전 상위 모델 GPT-3 수준을 능가한다는 주장이다.
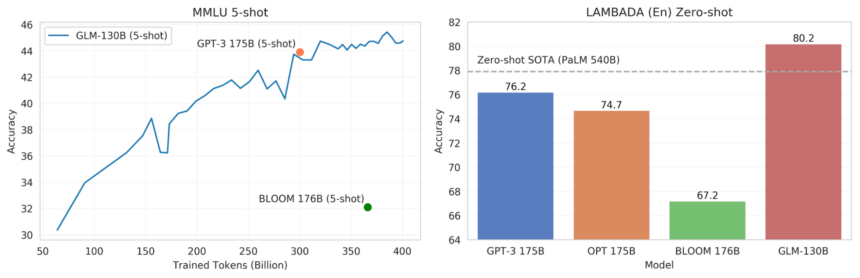
일련의 단어에서 마지막 단어를 예측하기 위한 제로샷 벤치마크인 LAMBADA에 대해 GLM-130B를 테스트한 결과에서도 이전까지 최상위였던 5400억개 매개변수를 지닌 구글의 PaLM을 능가했다고 덧붙였다.
중국이 대형 언어 모델 분야에서 서구 모델을 능가했다는 주장은 이번이 처음이다. GLM-130B는 깃허브 및 허깅페이스(HuggingFace)에서 사용할 수 있다.
한편 화웨이는 비슷한 시기에 PanGu-Alpha 모델을 기반으로하는 코드 모델 'PanGu-Coder'를 발표했다. PanGu-Coder는 오픈AI의 코덱스와 마찬가지로 텍스트 대신 코드를 데이터로 사용해 훈련하고 단어를 예측하듯이 코드를 완성한다. 3억 1700만에서 26억 매개변수에 이르는 여러 모델로 제공한다.
화웨이 측은 "이번에 발표한 코드 모델이 오픈 AI의 '코덱스'나 딥마인드의 '알파코드' 등과 대등하거나 높은 수준"이라고 자신했다.
AI타임스 박찬 위원 cpark@aitimes.com
[관련기사]아마존, 다국어 언어 모델 AlexaTM 공개
[관련기사]GPT-4에서 무엇을 기대할 수 있을까?
- 깃허브, 코덱스 기반 노코딩 AI ‘코파일럿’ 정식 출시
- 메타, 언어 모델 OPT-175B 무료 공개
- 구글, 5400억 매개변수 초대형 언어 모델 ‘PaLM’ 공개
- 카카오 T 앱, 유럽 진출한다..."9월부터 독일서 로밍 서비스 시작"
- 네이버, 인천재능대와 협력해 초대규모 AI 인재 양성
- “일자리 오히려 늘 것”...AI가 업무에 미치는 영향
- 바이든 정부, 미국산 AI 칩 중국 수출 금지
- 미국이 탈중국하기 어려운 이유
- 美 AI칩 수출금지, 中 대학 및 연구기관에 직격탄
- 중국, AI 분야 세계 최고 대학 순위에서 미국 압도
- AI 연구 중국이 세계 최강...양과 질 모두 미국 압도
